Welcome, I tried to extract the tables from the pdf, but if the table does not contain any bounds, then it doesn't get extracted, so I want to extract the text and the Seq2Seq model predicts the columns and rows, How can I do that?!
I'm trying to train a Seq2Seq model from simpletransformers but it's not working,
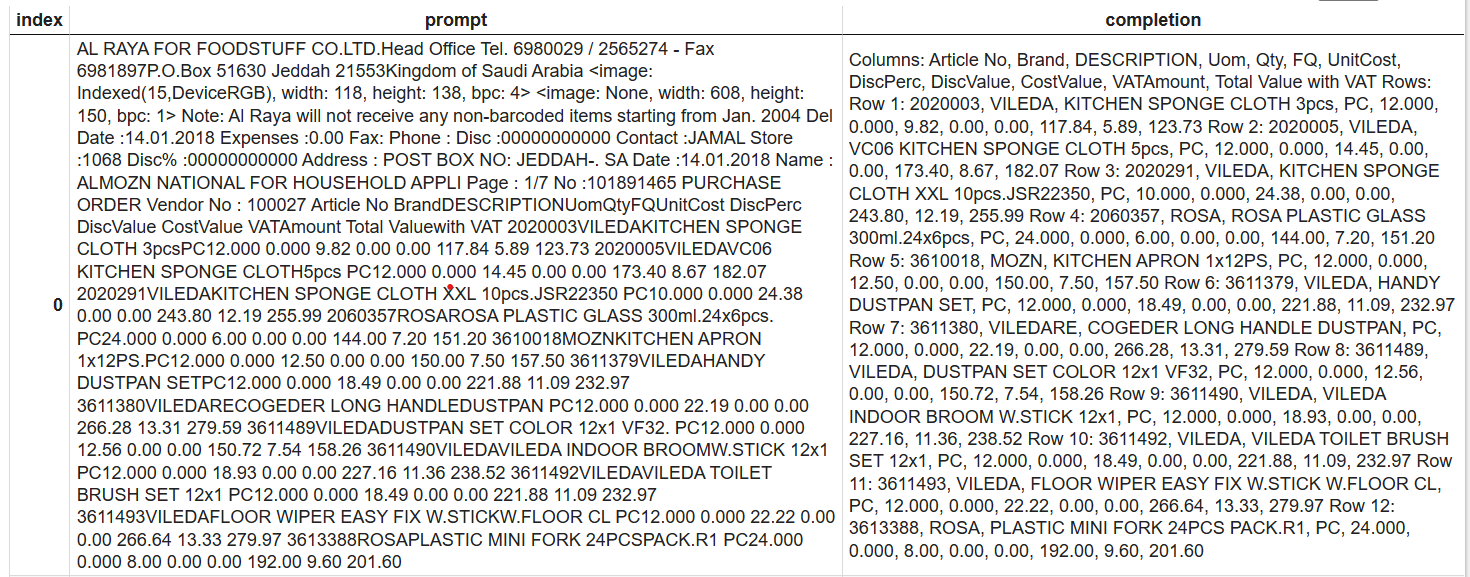
this is my training data, it's like this:
this is my Seq2Seq code:
model_args = Seq2SeqArgs()
model_args.num_train_epochs = 100
model_args.evalAuate_generated_text = True
model_args.evaluate_during_training = True
model_args.evaluate_during_training_verbose = True
model_args.max_length = 4096
model_args.train_batch_size = 16
model_args.eval_batch_size = 16
model_args.no_save = True
model_args.length_penalty = 3.0
model = Seq2SeqModel(
encoder_decoder_type="bart",
encoder_decoder_name="facebook/bart-large",
args=model_args,
use_cuda=True,
)
and this is the output I got:
